Today, we have two big announcements:
1️⃣ SuperDuperDB is now Superduper!
2️⃣ Introducing Our Enterprise Solution
We are excited to announce the launch of our enterprise solution on top of our open-source project, designed for scalable custom AI on major databases.
Rebranding to Superduper
With our new branding as "Superduper," we emphasize that we are not just a database but a comprehensive platform for integrating AI models and workflows with major databases. Our partnerships include:
- MongoDB
- Snowflake
- Postgres
- MySQL
- SQLite
- DuckDB
- BigQuery
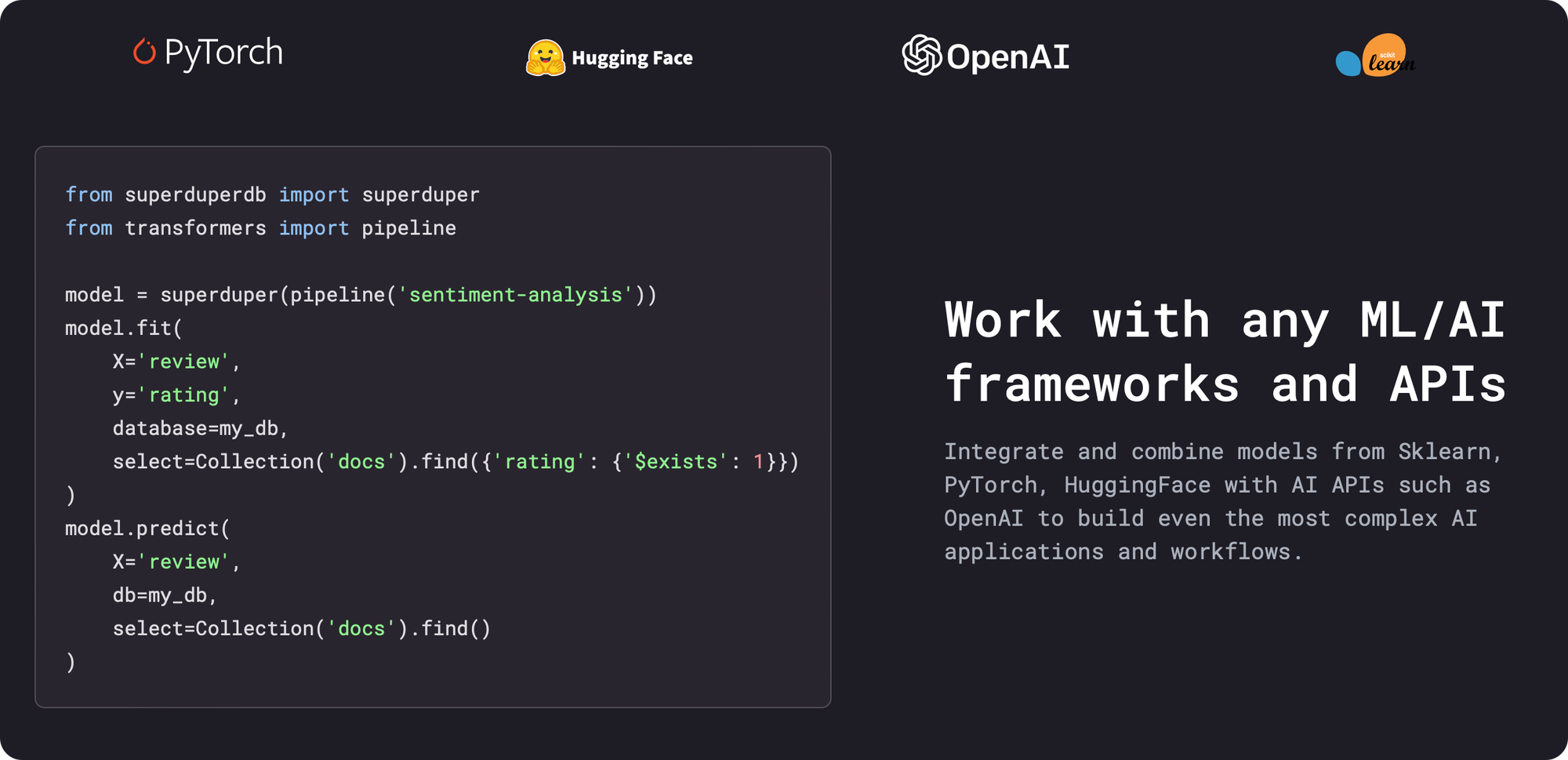
Superduper supports everything from Generative AI (GenAI) and Large Language Models (LLMs) to classic machine learning.
New Enterprise Offering
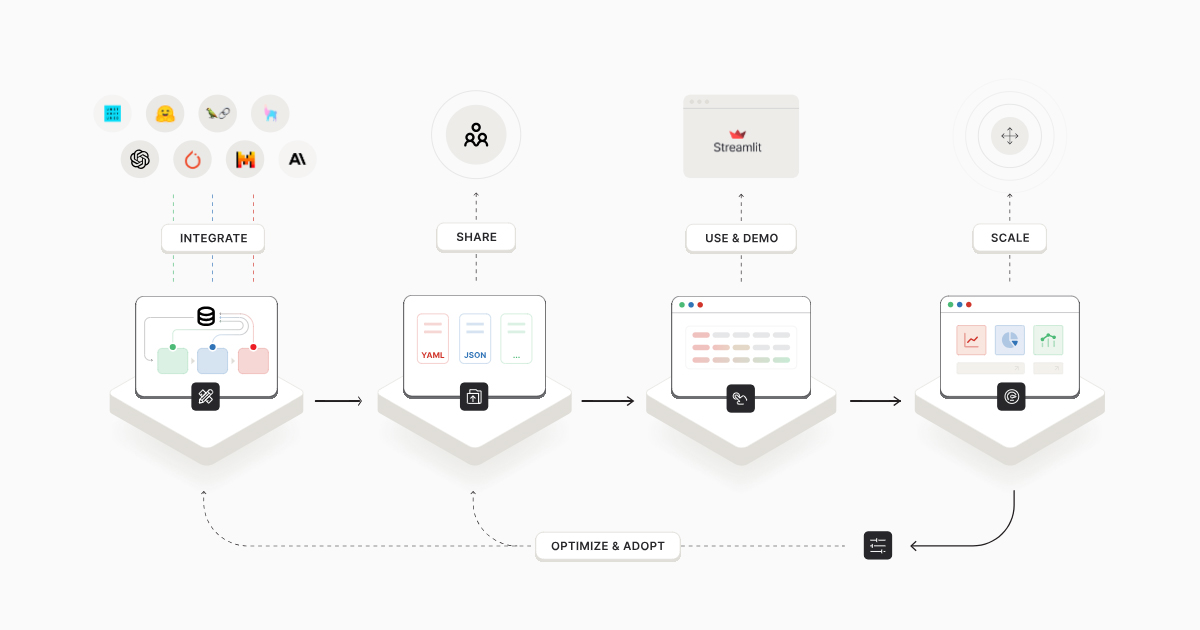
Our enterprise solution empowers AI teams to deploy and scale AI applications built with our open-source development framework on a single platform. This can be done across any cloud or on-premises environment, with compute running where the data resides to minimize data movement.
Key Features:
- Superduper App and Workflow Templates: Ready-to-install on the database and fully configurable. Enterprises can adopt custom AI solutions with minimal development work.
- Use Cases: Current applications include multi-modal vector search & Retrieval-Augmented Generation (RAG), document extraction & analysis, anomaly detection, visual object detection, image search, and video search.
Transforming AI-Application Development
Superduper is on a mission to transform AI-application development by eliminating the need for traditional MLOps and ETL pipelines. Instead, developers can simply install AI components directly on their databases. This is a significant shift, allowing developers to focus on selecting the best AI models and crafting optimal queries, without worrying about infrastructure, MLOps, or specialized vector databases.
The Superduper Advantage
By making the database the central AI platform, Superduper consolidates enterprise AI, removing unnecessary complexity from the AI-data stack. This approach ensures that AI development is secure, efficient, and rapid:
- No Pipelines or Data Migration: All AI application steps begin and end with the database.
- Enhanced Data Security: Keeping everything within the database enhances data security.
- Reduced Time-to-Production: Streamlining the process results in faster deployment.
- Composability: Superduper's declarative model allows for fully composable, database-backed AI applications. Developers can mix and match open and closed-source components, avoiding vendor lock-in, reducing costs, and maintaining control over their data and AI stack.
Get in Touch
We're eager to discuss your AI use cases and demonstrate how Superduper can address them. Visit our new website at superduper.io to learn more!
Share this announcement to help us spread the word to the community!
#superduper #ai #mlops #mongodb #snowflake #postgres #mysql