

🔮TL;DR: We introduce SuperDuperDB, which has just published its first major v0.1 release. SuperDuperDB is an open-source AI development and deployment framework to seamlessly integrate AI models and APIs with your database. In the following, we will survey the challenges presented by current AI-data integration methods and tools, and how they motivated us in developing SuperDuperDB. We'll then provide an overview of SuperDuperDB, highlighting its core principles, features and existing integrations.
AI adoption is pressing, but difficult
AI is changing every industry and will soon play a central role in software products and services.
Developers today may already choose from a growing number of powerful open-source AI models and APIs. Despite this, there are numerous challenges which face developers when integrating AI with data and bringing machine learning models to production.
AI and data live in silos separate from one another
Data is crucial for AI, and, most importantly, connecting AI with data is vital for delivering value whether in training models or applying models to application-relevant data. A key problem stems from the disconnect between where data resides (in databases) and the lack of a standard method for AI models to interface with these databases. This results in convoluted MLOps pipelines, involving intricate steps, numerous tools, and specialized vector databases, and contributes to the status quo in which data and AI live in isolated silos.
Connecting AI with your data to build custom AI is a big challenge
Current solutions require extracting data from the database, and bringing it to AI models. More specifically, extracted data is ingested into complex “MLOps” and “extract-transform-load” (ETL) pipelines that involve various steps, tools, and even specialized “vector-databases” and “feature-stores”. These convoluted pipelines involve sending the data back and forth, from one environment, format, location, or programming language to another.
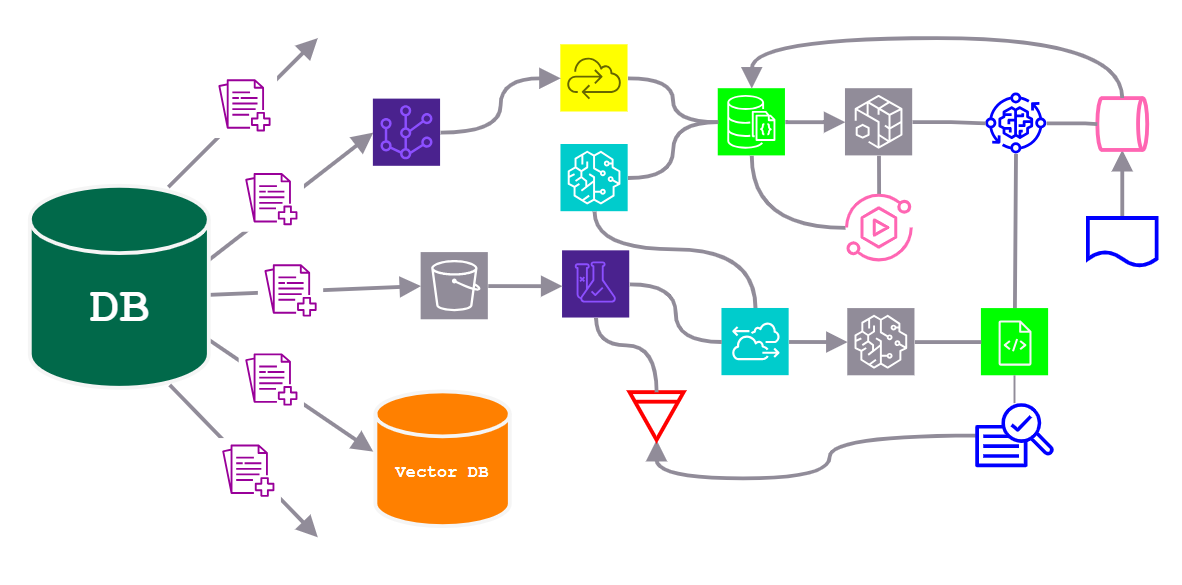
In setting up these pipelines, developers are forced to implement a different version of the same task every time they wish to productionize an AI model. Each sub-step of this process may involve multiple sets of installation targets, cloud setups, docker containers, and computational environments. Since every model has its own particular interface and requirements, this leads to huge operational and infrastructural overhead, which multiplies with the number of models, data types, databases, and hardware requirements.
This becomes increasingly difficult when:
- data is constantly updated and changing
- data resides in multiple locations,
- data security restrictions disallow the use of AI APIs and require end-to-end self hosting.
Due to this complexity, both individual developers and teams often struggle to put AI-powered applications into production, lacking the required expert knowledge in various domains, and unable to meet the prohibitive costs of deploying and maintaining such pipelines.
Low-code AI tools and cloud-managed AI often don’t fit the bill
A new wave of AI companies and services offer "few-click" interfaces and "low-code markups" to ease AI-data integration for certain use-cases. However, these fall short of wide applicability. User-interfaces are typically too far removed from the nuts and bolts of AI models to become broadly useful; low-code mark-up languages hide the most important details of AI implementation from the user and render it impossible to override baked in defaults. This means that as soon as an application departs from the most commonly used and documented AI use-cases, developers are left without options for customization.
On the other hand, services of the major cloud providers also make the promise to simplify AI and data integration. These offerings presents two major issues: developers are encouraged to give up full ownership of their stack, leading to costly vendor lock-in. What’s more, these services do little more than repackage traditional MLOps and ETL pipelines, still resulting in substantial developer overhead.
The problem with vector databases
The popularity of vector-databases, alongside tools such as LangChain and LlamaIndex, has surged in 2023. This boom has been fuelled by the prospect of combining vector-searches with LLMs and the fact that standard databases lack the necessary vector-search functionality, model support, and support for flexible data types required. While these tools allow developers to get started with vector-search quickly, the reality is that, in production, primary data resides in, and will most likely remain in established databases. This means that developers are required to introduce an additional specialized database, for this single purpose, to their stacks, leading to data duplication, migration, and management overhead. If data is already stored in an existing, preferred and battle-tested database, then why not simply leave the data there?
Unifying data and AI
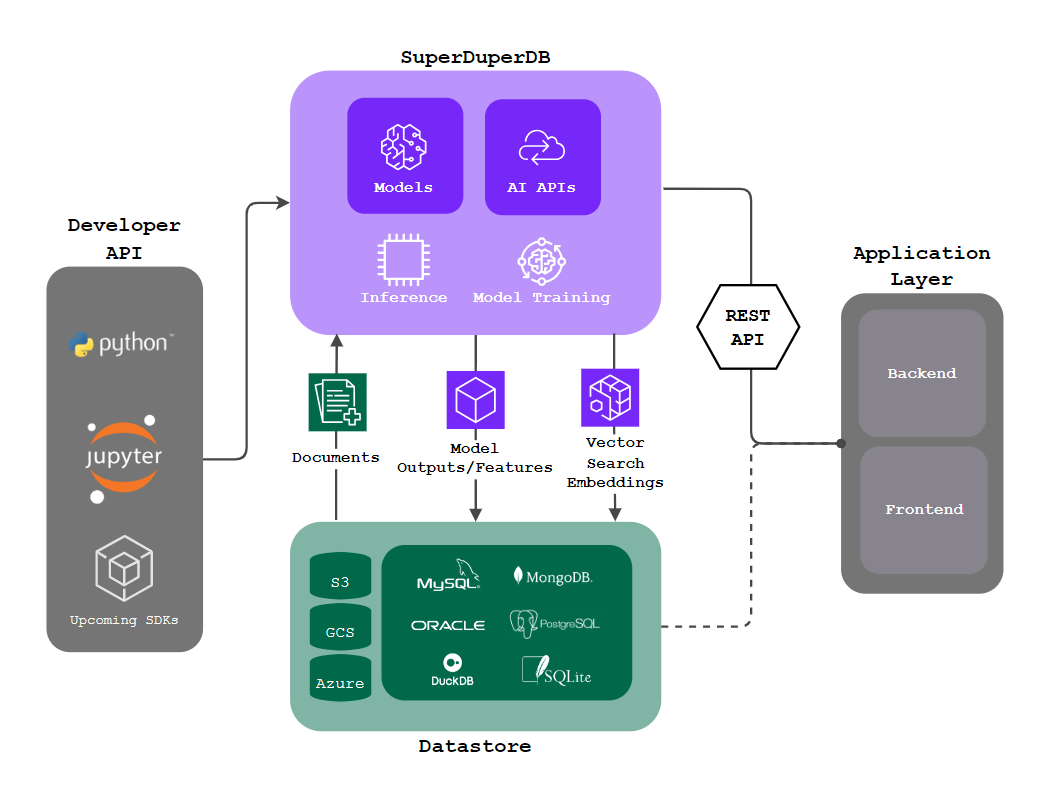
We believe, unifying data and AI in a single environment is the key to facilitating AI adoption. By doing this, the difficulties encountered with MLOps, ETL and vector-databases can be completely avoided.
Specifically, developers need an environment that can work directly with data in the database, enabling flexible integration of AI models, and vector-search, with minimal boilerplate. Ideally this environment should allow developers to connect a model to the database, so that it automatically processes incoming data, making economical use of resources.
Enter SuperDuperDB
SuperDuperDB’s mission is to bring AI to the database, making data migration, data duplication, MLOps, and ETL pipelines things of the past.
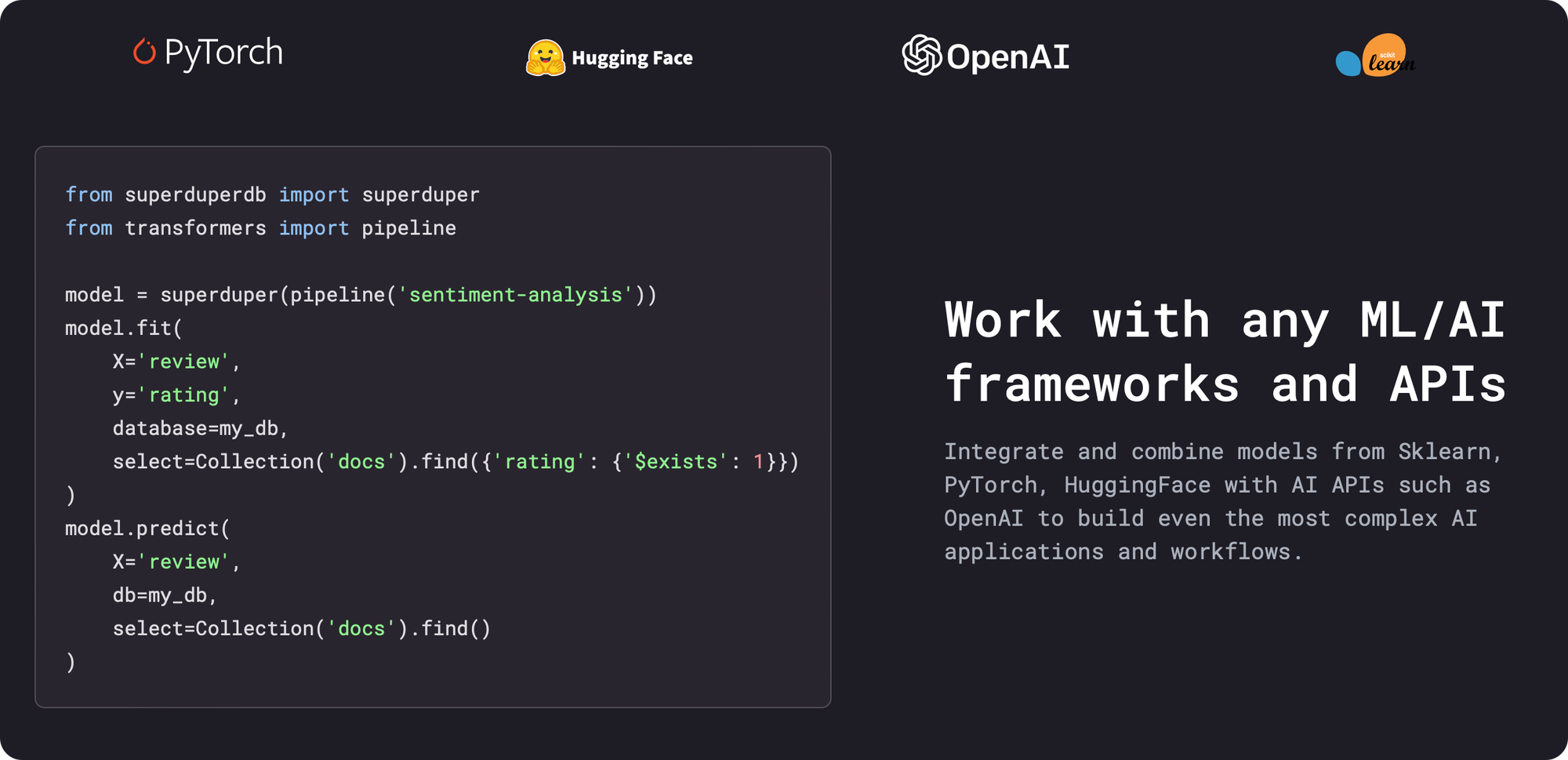
SuperDuperDB is a general-purpose AI development and deployment framework for integrating any AI models (including enhanced support for PyTorch, Scikit-Learn, Hugging Face) and AI APIs (including enhanced support for OpenAI, Anthrophic, Cohere) directly with existing databases, including streaming inference, model training, and vector search. SuperDuperDB is not a database, it makes your existing databases “super-duper”.
from superduperdb import superduper
# Make your database super-duper!
db = superduper('mongodb|postgres|duckdb|snowflake|://<connection-uri>')
By bringing AI directly to data, solo developers and organizations can avoid the complexity of building and integrating MLOps and ETL pipelines as well as migrating and duplicating data across multiple environments, including specialized vector databases. SuperDuperDB enables the integration of AI with data in the database, storing AI model outputs alongside the source data. These insights and AI outputs are then ready for instant deployment in downstream applications.
SuperDuperDB provides a unified environment for building, shipping, and managing AI applications, including first-class support for:
- Generative AI & LLM-chat applications
- Vector search
- Standard machine learning use-cases (classification, segmentation, recommendation, etc.)
- Highly custom AI use-cases involving application specific, home-grown models.
🔮 Please support us by leaving a star the GitHub repo and share it with anyone who could be interested: https://github.com/SuperDuperDB/superduperdb
Core principles and features of SuperDuperDB
Open source
We believe AI software should be open-sourced to the community. Truly open-source tools are the only sure way for developers to protect their stacks from vunerable dependencies.
With SuperDuperDB, we are excited to be part of a thriving open-source AI ecosystem. There is a wealth of open-source AI software and models available, including transformers from Hugging Face, llama-2.0 and other LLMs that can compete with OpenAI's closed source models, computer vision models in PyTorch, and a plethora of new open-source tools and models emerging from GitHub.
SuperDuperDB is permissively open-sourced under the Apache-2.0 license, and aims to become a leading standard in adopting and extracting value from this ecosystem.
Python first
Many tools on the AI landscape encourage developers to move away from Python, in favour of specialized user-interfaces, or specific mark-up languages only relevant to the tool in question. This not only ignores the important fact that Python is the programming language of AI research, development and tooling, but the advertised simplicity comes at the great cost of flexibility.
By building SuperDuperDB as an open-source Python package, we are able to provide a simple interface with high-level abstractions for users who wish to get started quickly with AI models, but enabling experts to drill down to any level of implementation detail.
By deploying models directly to the database from Python, there is no overhead incurred by task-switching to other programming languages or environments. Using SuperDuperDB developers may:
- add, leverage and work with any function, program, script or algorithm from the Python ecosystem to enhance workflows and applications.
- retain full control over the inner workings of models and training configurations
- combine SuperDuperDB with favoured tooling such as the vastly popular FastAPI. (See here for an open-source chatbot implementation based on SuperDuperDB and FastAPI, which showcases how easily SuperDuperDB and the Python ecosystem interact.)
- interface with their database using SuperDuperDB directly from a Jupyter notebook - the data scientist’s development environment of choice.
Avoid complex pipelines
Arbitrary pipeline builders, as offered in typical MLOps tooling, typically consist of repeated rounds of ETL, with a variety of models and processors. By understanding the patterns which AI developers typically apply, we were able to build a framework which avoids the necessity of pipeline building while leveraging compute in the most efficient way possible.
As a result, SuperDuperDB allows developers to:
- avoid data duplication and migration.
- avoid additional pre-processing steps, ETL, and boilerplate code.
- activate models to compute outputs automatically as new data arrives, keeping deployments up-to-date.
- train AI models on large datasets, utilizing the in-built scalability of SuperDuperDB.
- set up complex workflows by connecting models and APIs to work together in an interdependent and sequential manner.
Avoid specialized vector databases
With SuperDuperDB, there is no need to duplicate and migrate data to additional specialized vector databases — your existing database becomes a fully-fledged multi-modal vector-search database, with support for arbitrary data types, and generation of vector embeddings and vector indexes of your data with arbitrary AI models and APIs.
Support for arbitrary data types
SuperDuperDB supports images, video, and arbitrary data-types which may be defined in Python; this includes efficient use of hybrid database-filesystem storage, allowing developers to make the most effective use of storage modalities and achieve great I/O performance.
First-class support for generative AI as well as classical machine learning
SuperDuperDB levels the playing field for all AI models, regardless of complexity. Setting up applications such as retrieval-augmented-generation (RAG) chatbots, which combine generative AI and vector search, is as easy as setting up a wide range of industry use-cases involving tabular data, time-series, and more, all of which still hold immense value. Even applications that combine generative AI with classical ML algorithms can be seamlessly integrated into a single workflow.
Current Integrations:
Datastores:

AI Frameworks & APIs:


Use-cases and applications
We have already implemented numerous use-cases and applications, such as LLM RAG chat, forecasting, recommenders, sentiment analysis which you can refer to in the README of our main repository and in our example use cases documentation
In addition, we already have several impressive applications and use-cases built by the open-source community, which we are excited to present in our dedicated community apps showcase repo: SuperDuperDB Community Apps.
Vision, roadmap, and how to get started
After reviewing the use cases, you’ll be ready to build your own AI applications using your own database. For assistance, please refer to our documentation and join our Slack. We would also love to hear about your project and help you to share it with the community.
The current focus of the roadmap is making the deployment of SuperDuperDB absolutely production-ready and to improve optimizations for deployment, compute efficiency and scalability.
❤️🔥 If you haven’t yet, now is the time to leave a star on GitHub to support the project and share it with your friends and colleagues: https://github.com/SuperDuperDB/superduperdb