

Querying your SQL database purely in human language

Unless you live under a rock, you must have heard the buzzword “LLMs”.
It’s the talk around town.
LLM models, as we all know, have so much potential. But they have the issue of hallucinating and a knowledge cut-off.
The need to mitigate these two significant issues when using LLMs has led to the rise of RAGs and the implementation of RAGs in your existing database.
What is RAG?
Let’s paint a picture.
Let’s say you work for an e-commerce company. And you want the non-technical marketing personnel to be able to get updated customer shopping information from the database at will.
A straightforward way is to build a system that lets them chat with the database in natural human language a.k.a RAG.
RAG, which stands for Retrieval-Augmented Generation, is a method used in natural language processing (NLP) to enhance the capabilities of language models. It combines the power of two distinct components: a retriever and a generator. The retriever is used to fetch relevant context or documents from a large corpus of text, and the generator is then used to produce a coherent and contextually relevant output based on both the input query and the retrieved documents.
To build a RAG system, you need two major things
-
A database with a vector search functionality
-
LLM model(s)
One popular and fast OLAP database that fits this use case perfectly is DuckDB.
DuckDB is an in-process SQL OLAP (Online Analytical Processing) database management system. It’s designed to be fast and easy to use, focusing on data analytics. Unlike traditional OLTP (Online Transaction Processing) databases optimized for transactional workloads, OLAP databases like DuckDB are optimized for complex queries and aggregations typical in data analysis tasks.
Find more information about DuckDB here
At the moment**, DuckDB** does not have native vector-search support.
SuperduperDB will help with extending this functionality to DuckDB.
SuperDuperDB is a Python framework designed to integrate AI models, APIs, and vector search engines with existing databases directly. It supports hosting your models, streaming inference, and scalable model training/fine-tuning. The framework aims to simplify the process of building, deploying, and managing AI applications without complex pipelines or specialized infrastructure. SuperDuperDB enables the integration of AI and vector search directly with databases, facilitating real-time inference and model training, all while using Python. This makes building and managing AI applications easier without moving data to complex pipelines and specialized vector databases.
SuperduperDB can enhance the lightweight, fast nature of DuckDB by adding a vector search functionality and AI models to the database in a few simple steps.
SuperduperDB also supports other popular databases, like MongoDB, Postgres, Mysql etc. More info about SuperDuperDB data integration can be found here
The Jina Embeddings v2 will be used as an embedding model to be used to generate vector embeddings on the existing data.
Jina AI offers a top-tier embedding model: Jina Embeddings v2, designed to enhance search and retrieval systems with 1 million free tokens for new API keys, facilitating personal and commercial projects without requiring a credit card. This model stands out for its deep integration of cutting-edge academic research and rigorous testing against state-of-the-art (SOTA) models, ensuring exceptional performance. It is the first open-source model to support an 8192-token length, representing entire chapters within a single vector. The model supports multilingual embeddings, including German-English, Chinese-English, and Spanish-English, making it ideal for cross-lingual applications. It also boasts seamless integration capabilities, fully compatible with OpenAI’s API and easily integrating with over ten vector databases and retrieval-augmented generation (RAG) systems, ensuring a smooth and efficient user experience.
Jina AI mission is to lead the advancement of multimodal AI through innovative embedding and prompt-based technologies, focusing specifically on areas like natural language processing, image and video analysis, and cross-modal data interaction.
Find more information about Jina here.
In this use case, the retriever will be our vector search, and our generator will be OpenAI’s ChatGPT model (LLM), which will synthesize the output retrieved from the vector search.
The architecture would look something like this.

The data we will be ingesting into the database will be from Kaggle, which has 17 columns that consist of customer shopping habit details.
import pandas as pd
shopping_df = pd.read_csv("shopping_trends.csv")
shopping_df.info()
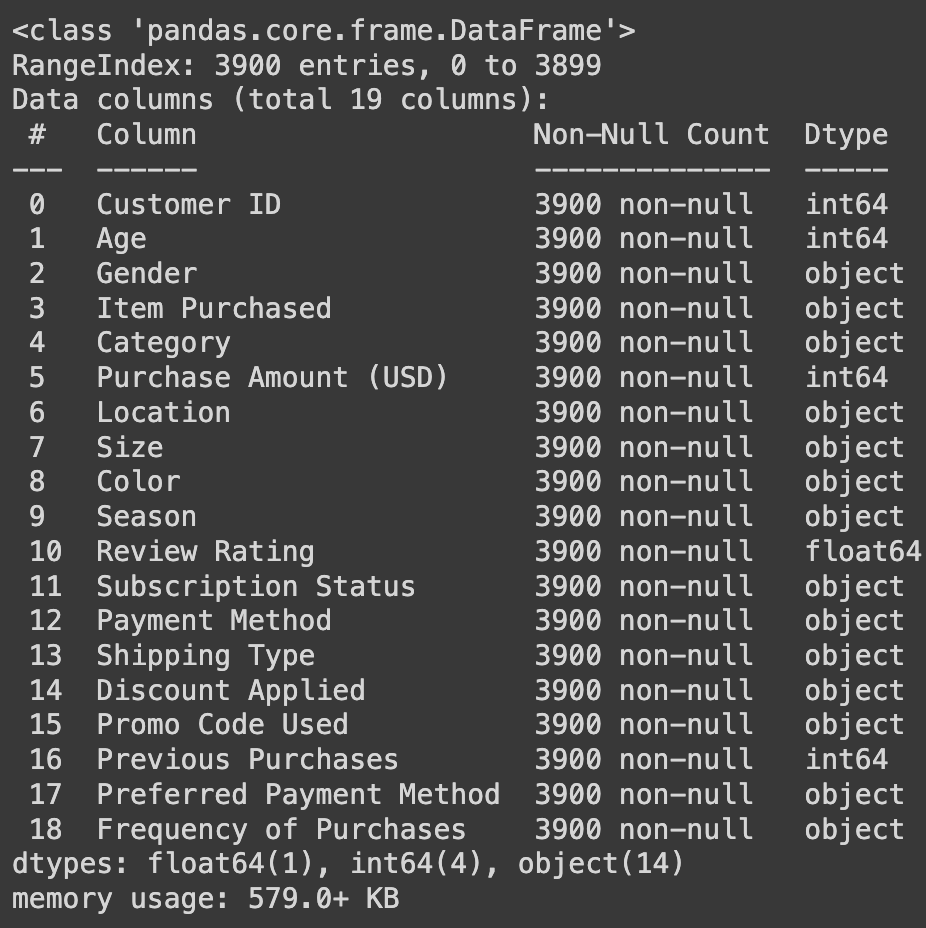
We will add a column called “Description”, which contains the description of each row.
def create_description(row):
description = f"Customer {row['Customer ID']} is a {row['Age']}-year-old {row['Gender']} who purchased a {row['Color']} {row['Item Purchased']} from the {row['Category']} category for ${row['Purchase Amount (USD)']}. "
description += f"The purchase was made in {row['Season']} from {row['Location']} in size {row['Size']}. "
description += f"Review rating was {row['Review Rating']}, and the purchase method was {row['Payment Method']} with {row['Shipping Type']} shipping. "
description += f"Discounts applied: {row['Discount Applied']}, Promo code used: {row['Promo Code Used']}. "
description += f"Customer has made {row['Previous Purchases']} previous purchases and prefers {row['Preferred Payment Method']} with a purchase frequency of {row['Frequency of Purchases']}. Subscription status: {row['Subscription Status']}."
return description
# Apply the function to create the description column
shopping_df['Description'] = shopping_df.apply(create_description, axis=1)
print(shopping_df['Description'][0])

Now, let's get started.
Our RAG System implementation would be in 5 steps
-
Install the necessary libraries and set the environment variable
-
Connect DuckDB to SuperDuperdb
-
Define the schema of the data
-
Add a vector index and an embedding model to the database
-
Add ChatGPT Model to the database
Step-by-step:
- Install the necessary libraries and set the environment variables.
We would be using the Ibis framework to install DuckDB. Ibis is a Python library for data analysis that offers a pandas-like syntax better suited for big data systems. More info about it here here
! pip install "ibis-framework[duckdb]"
! pip install superduperdb
! pip install openai
! pip install jina
import os
os.environ['OPENAI_API_KEY'] = 'OPENAI-API'
os.environ['JINA_API_KEY'] = 'JINA-API'
- Connect DuckDB to SuperDuperDB using a DuckDB URI.
For this use case, we use Lance as the vector-search backend for DuckDB. We would also define an artifact store path locally and a metadata store path using SQLite.
from superduperdb import superduper
from superduperdb import CFG
CFG.force_set('cluster.vector_search', 'lance')
artifact_store = 'filesystem://./my'
metadata_store ='sqlite:///my.sqlite'
duckdb_uri = 'duckdb://my.ddb'
db = superduper(duckdb_uri, metadata_store=metadata_store, artifact_store=artifact_store)
You can view the configuration this way below.
print(CFG)

However, these configurations are optional. Alternatively, you can skip setting configuration and just connect to SuperDuperDB this way.
duckdb_uri = 'duckdb://my.ddb'
db = superduper(duckdb_uri)
print(CFG)

If none of these configurations are set, it defaults to in-memory vector search. Also, the metadata and artifact store path are None
- Define the table and schema. Add them as well as data to the database
Defining the schema involves defining a table name, a unique identifier of the table as the primary key, a schema name, the column names, and their respective datatypes.
from superduperdb.backends.ibis.query import Table
from superduperdb.backends.ibis.field_types import dtype
from superduperdb import Schema
shopping_table = Table(
'shopping_table', #tablename
primary_id='Customer ID', #unique identifier
schema=Schema(
'shopping-schema', #schema name
)
)
db.add(shopping_table)
Next, add the Dataframe data to the DB.
_ = db.execute(shopping_table.insert(shopping_df))
You can view the five rows of the table like this.
list(db.execute(shopping_table.limit(5)))

- Add the Jina AI embedding model and the vector index to the database
*The **“Jina Embeddings v2” **would be used to create the vector embedding on the **“Description” *column on the “shopping_table”.
from superduperdb.ext.jina import JinaEmbedding
# define the model
model = JinaEmbedding(identifier='jina-embeddings-v2-base-en')
*The **Listener function **is used to listen to user queries and convert the queries to vectors automatically using the embedding model. *
from superduperdb import VectorIndex, Listener
# define the listener
listener = Listener(model=model,key='Description',select=shopping_table)
# define the vector index
db.add(VectorIndex(identifier='my-duckdb-index', indexing_listener= listener))
More information about Listener can be found here.
At this stage, an embedding of all the rows in the description column is automatically populated.
- Add the ChatGPT model to the database.
from superduperdb.ext.openai import OpenAIChatCompletion
# Define the prompt for the OpenAIChatCompletion model
prompt = (
'Use the following context to answer this question\n'
'Do not use any other information you might have learned \n'
'Check the context and filter out results that do not match the question'
'Only base your answer on the context retrieved\n'
'{context}\n\n'
'Here\'s the question:\n'
)
# Create an instance of OpenAIChatCompletion with the specified model and prompt
chat = OpenAIChatCompletion(identifier="chatgpt_model", model='gpt-3.5-turbo', prompt=prompt)
# Add the instance to the database
db.add(chat)
Excellent, you have built a simple RAG.
Let’s test it by creating a simple function that helps to interact with the RAG system.
from superduperdb import Document
model_identifier = 'chatgpt_model'
column_to_vectorize = 'Description'
vector_index_identifier = 'my-duckdb-index'
def chat_with_database(search_term,
model_identifier = model_identifier,
column_to_vectorize = column_to_vectorize,
vector_index_identifier = vector_index_identifier):
# Use the SuperDuperDB model to generate a response based on the search term and context
output, context = db.predict(
model_name=model_identifier,
input=search_term,
context_select=(
shopping_table
.like(Document({column_to_vectorize: search_term }), vector_index=vector_index_identifier)
.limit(5)
),
context_key=column_to_vectorize,
)
return output.content
The function above will be the function that would be called as soon as the user or marketing personnel types something related to the database data.
To call the function, use the code below.
user_query = 'Find me Customers between age 20 and 28 and with size L'
print(chat_with_database(user_query)

The above shows the results of the query
To check how many models are in your Database, use the code below
print(db.show('model'))
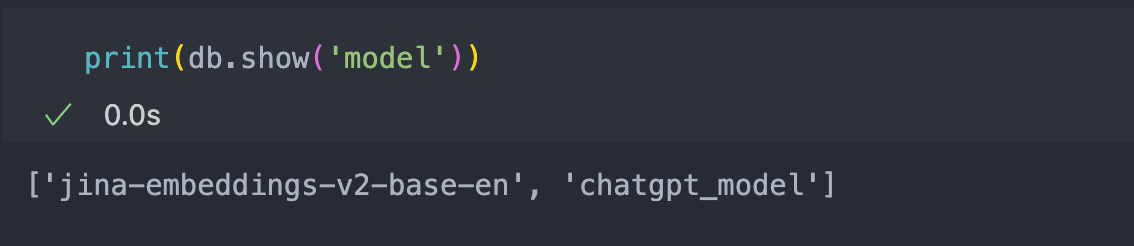
The above shows that two models are simultaneously in the database (the Jina Embeddings v2 and the ChatGPT model).
Conclusion
Now that you have built and implemented your RAG system, the next step would be to wrap it all in a user interface. And then, you would have a system that helps non-technical chat with your Database purely in human language using Jina AI and SuperDuperDB.
Check out the Jina AI open-source repo and SuperDuperDB open-source repo to stay updated on more functionalities.
Useful Links
Contributors are welcome!
SuperDuperDB is open-source and permissively licensed under the Apache 2.0 license. We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on GitHub!