

In step-by-step tutorial we will show how to leverage MongoDB Atlas Vector Search with SuperDuperDB, including the generation of vector embeddings. Learn how to connect embedding APIs such as OpenAI or use embedding models for example from HuggingFace with MongoDB Atlas with simple Python commands.
SuperDuperDB makes it very easy to set up multimodal vector search with different file types (text, image, audio, video, and more).
Install superduperdb Python package
Using vector-search with SuperDuperDB on MongoDB requires only one simple python package install:
pip install superduperdb
With this install SuperDuperDB includes all the packages needed to define a range of API based and package based
vector-search models, such as OpenAI and Hugging-Face's transformers.
Connect to your Atlas cluster using SuperDuperDB
SuperDuperDB ships with it's own MongoDB python client, which supports
all commands supported by pymongo. In the example below
the key to connecting to your Atlas cluster is the db object.
The db object contains all functionality needed to read and write to
the MongoDB instance and also to define, save and apply a flexible range
of AI models for vector-search.
from superduperdb.db.base.build import build_datalayer
from superduperdb import CFG
import os
ATLAS_URI = "mongodb+srv://<user>@<atlas-server>/<database_name>"
OPENAI_API_KEY = "<your-open-ai-api-key>"
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
CFG.data_backend = ATLAS_URI
CFG.vector_search = ATLAS_URI
db = build_datalayer()
Load your data
You can download some data to play with from this link:
curl -O https://superduperdb-public.s3.eu-west-1.amazonaws.com/pymongo.json
The data contains all inline doc-strings of the pymongo Python API (official
MongoDB driver for Python). The name of the function or class is in "res" and
the doc-string is contained in "value".
import json
with open('pymongo.json') as f:
data = json.load(f)
Here's one record to illustrate the data:
{
"key": "pymongo.mongo_client.MongoClient",
"parent": null,
"value": "\nClient for a MongoDB instance, a replica set, or a set of mongoses.\n\n",
"document": "mongo_client.md",
"res": "pymongo.mongo_client.MongoClient"
}
Insert the data into your Atlas cluster
We can use the SuperDuperDB connection to insert this data
from superduperdb.db.mongodb.query import Collection
collection = Collection('documents')
db.execute(
collection.insert_many([
Document(r) for r in data
])
)
Define your vector model and vector-index
Now we have data in our collection we can define the vector-index:
from superduperdb.container.vector_index import VectorIndex
from superduperdb.container.listener import Listener
from superduperdb.ext.numpy.array import array
from superduperdb.ext.openai.model import OpenAIEmbedding
model = OpenAIEmbedding(model='text-embedding-ada-002')
db.add(
VectorIndex(
identifier=f'pymongo-docs',
indexing_listener=Listener(
model=model,
key='value',
select=Collection('documents').find(),
predict_kwargs={'max_chunk_size': 1000},
),
)
)
This command tells the system that we want to:
- search the
"documents"collection - set-up a vector-index on our Atlas cluster, using the text in the
"value"field - use the OpenAI model
"text-embedding-ada-002"to create vector-embeddings
After issuing this command, SuperDuperDB does these things:
- Configures an MongoDB Atlas knn-index in the
"documents"collection - Saves the
modelobject in the SuperDuperDB model store hosted ongridfs - Applies
modelto all data in the"documents"collection, and saves the vectors in the documents - Saves the fact that
modelis connected to the"pymongo-docs"vector-index
You can confirm that the index has been created and view the index's settings in the Atlas UI. It should look like this:
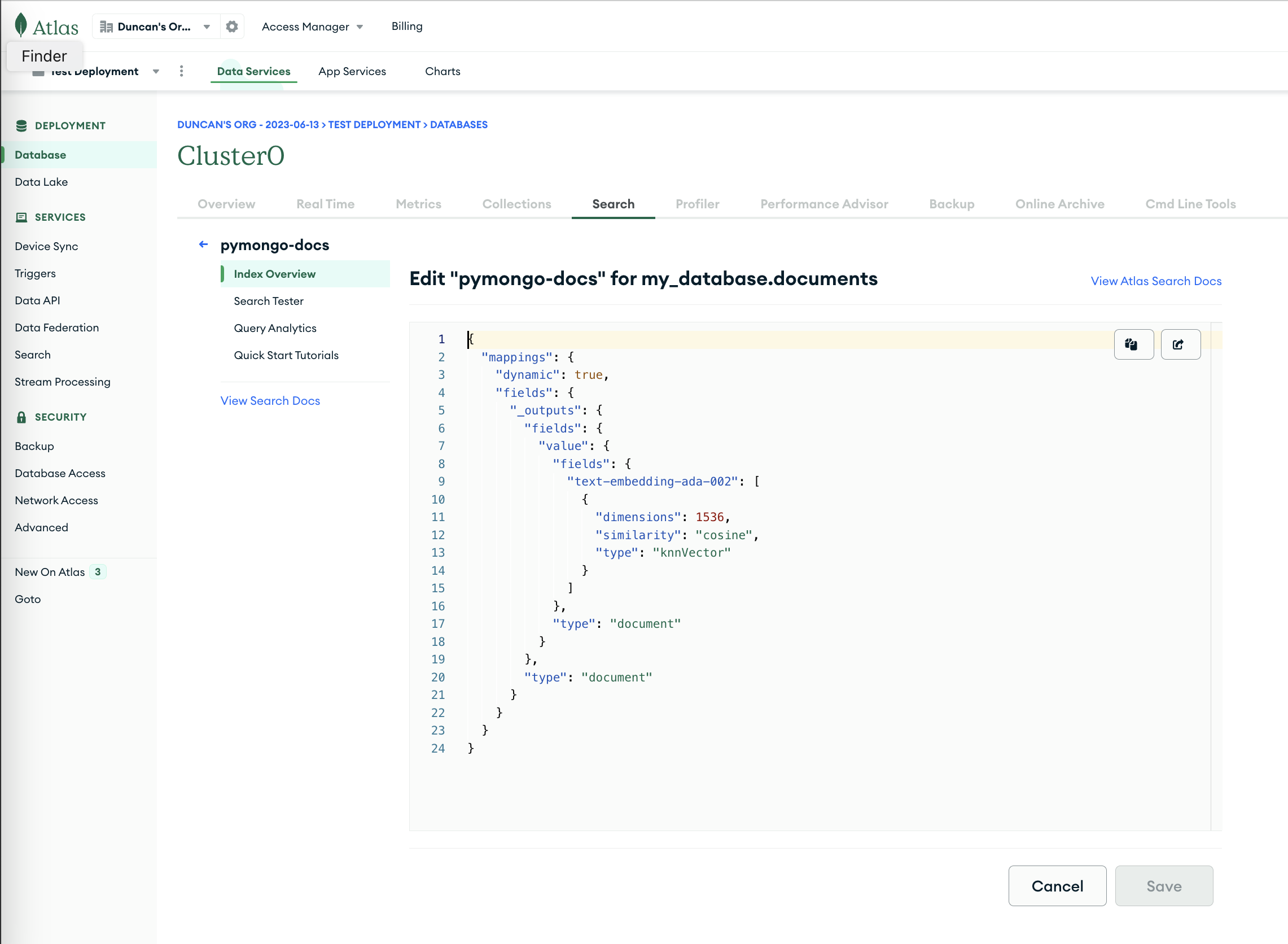
The nesting of the index signifies the fact that the index created looks
into the _outputs.<key>.<model-name> path, which is where the model's vector outputs are stored
automatically by SuperDuperDB.
Use vector-search in a super-duper query
Now we are ready to use the SuperDuperDB query-API for vector-search. You'll see below, that SuperDuperDB handles all logic related to converting queries on the fly to vectors under the hood.
from superduperdb.db.mongodb.query import Collection
from superduperdb.container.document import Document as D
from IPython.display import *
query = 'Find data'
result = db.execute(
Collection('documents')
.like(D({'value': query}), vector_index='pymongo-docs', n=5)
.find()
)
for r in result:
display(Markdown(f'### `{r["parent"] + "." if r["parent"] else ""}{r["res"]}`'))
display(Markdown(r['value']))
Useful Links
Contributors are welcome!
SuperDuperDB is open-source and permissively licensed under the Apache 2.0 license. We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on GitHub!
Become a Design Partner!
We are looking for visionary organizations which we can help to identify and implement transformative AI applications for their business and products. We're offering this absolutely for free. If you would like to learn more about this opportunity please reach out to us via email: partnerships@superduperdb.com